Цифровой сервис для оценки удобочитаемости текстов на веб-сайтах вузов
Интерактивный цифровой инструмент для оценки удобочитаемости и визуального восприятия новостей пользователями веб-сайтов вузов.
Задача
Официальный веб-сайт для вуза – один из основных способов взаимодействия с внешней средой, инструмент поддержания имиджа, средство информирования и навигации. На сайт загружают новостной, образовательный и научный контент в рамках задач вуза по отношению по разным группам пользователей, таким как абитуриенты, студенты, в том числе и иностранные, их родители, профессорско-преподавательский состав, сотрудники администрации и различных административных отделов. Однако в новостных разделах от авторов требуется учитывать особенности каждой из аудиторий.
Поэтому был создан цифровой сервис PolyLing для оценки удобочитаемости и визуального восприятия текстов новостного раздела, учитывающий специфику именно вузовских новостей. Анализ удобочитаемости текста проводится с помощью нейросетевых технологий.
Сервис: https://polyling.spbpu.com/
Решение
PolyLing – это интерактивный цифровой инструмент, позволяющий оценить читаемость и воспринимаемость информационного материала в несколько кликов.
Общее описание
В основе цифрового сервиса – нейросетевая модель, для разработки которой был проведен сбор и анализ наиболее значимых метрик оценки качества текста для носителей русского языка и иностранных граждан, говорящих на нем. Цифровой сервис оценивает текст по двум показателям: лингвистическому и визуальному.
Лингвистический анализ учитывает лексико-грамматический состав предложений, метрики морфологической, лексической и синтаксической сложности, показатели связности и структурирования текста и дает оценку его удобочитаемости.
При анализе визуализации сервис отмечает уместность и расположение иллюстраций, оптимальный размер и тип шрифта и межстрочных интервалов и пр.
После анализа удобочитаемости и визуального восприятия цифровой сервис дает краткую рекомендацию по улучшению текста и его верстки на сайте.
Основные этапы проекта
- Собран и размечен по лингвистическим признакам уникальный корпус текстов, включающий в себя новостные статьи с веб-сайтов высших учебных заведений РФ;
- Разработана нейросетевая модель для автоматической оценки воспринимаемости и потенциала воздействия мультимодального электронного текста веб-сайтов на русском языке;
- Разработаны и внедрены в цифровой сервис модули для оценки мультимодальности (визуальной воспринимаемости контента) по URL-ссылкам на веб-сайтах вузов и в текстовых документах Word (*.docx-файлах).
Корпус текстов
Для достижения цели потребовалось собрать собственный корпус текстов статей, посвященных новейшим разработкам и исследованиям, новостям науки и образования, административной и студенческой жизни, а также международному сотрудничеству вузов. Было выбрано двадцать сайтов высших учебных заведений по всей Российской Федерации, с которых собрали более тысячи текстов для обучения двух нейросетевых моделей: модели, оценивающей восприятие текста респондентами, для которых русский язык является родным, и теми, кто изучает его как иностранный.
Наиболее оптимальным методом для сбора большого количества информации является автоматический парсинг – процесс сбора данных с последующей их обработкой и анализом, позволяющий упростить поиск и обработку контента и провести их в сжатые сроки.
В результате были собраны и распределены в обучающей выборке два отдельных корпуса текстов – для обучения нейросетевой модели по оценке удобочитаемости текста для русского языка как родного и русского языка как иностранного.
Нейросетевая модель
По итогам тестирования наиболее популярных моделей алгоритм CatBoost показал себя лучше остальных.
Основное преимущество заключается в том, что CatBoost может включать в данные категориальные и текстовые функции без дополнительной предварительной обработки. Прогнозы CatBoost в 20–40 раз быстрее, чем в других библиотеках повышения градиента с открытым исходным кодом.
Для обучения модели подавался набор данных размерностью 260 × 40, то есть 40 лингвистических характеристик, извлеченных из 260 текстов, а также сам векторизованный текст.
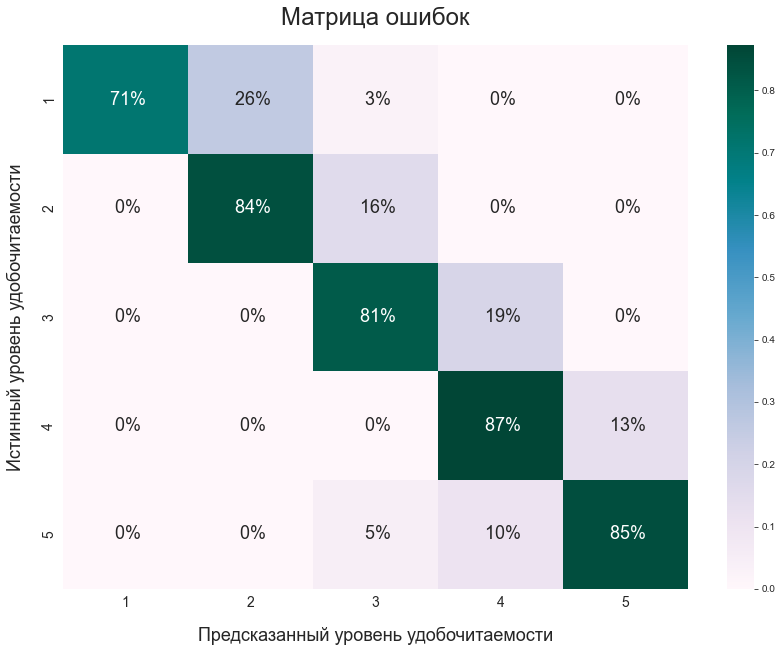
Матрица ошибок модели для оценки удобочитаемости текстов на русском языке для носителей
Матрица ошибок модели для оценки удобочитаемости текстов на русском языке как иностранном
Модель оценки мультимодальности текста
Оценка воспринимаемости текстов на сайтах высших учебных заведений обязательно должна учитывать не только сам текст, но и мультимодальность: находящиеся на странице объекты, например, изображения или видео-материалы, и иные параметры, такие как ширина текстового блока, шрифт, межстрочный интервал, цвет шрифта и фона и так далее. Все вышеуказанные данные содержатся либо в HTML-файлах, либо в уникальных для каждого сайта CSS-файлах, которые определяют стиль веб-страниц. Для демо-версии разработанного сервиса было решено собрать библиотеку из более чем тридцати популярных вузов РФ и дать пользователю возможность выбрать названия из этого списка. Для решения этой задачи были написаны следующие модули:
- Json-writer, который создает документ со списком вузов и их параметров, необходимых для оценки мультимодальности.
- Модуль, в котором происходят расчеты и который обращается к json-файлу, передавая ему название вуза, выбранного пользователем, и после этого выводя на экран информацию о приемлемости его визуального оформления, а также советы по улучшению текста.
Поскольку подготовка статьи для сайта включает в себя написание текста в собственном редакторе, разработанный ресурс также предусматривает предварительную обработку текстовый файлов в формате *.docx. Отдельный модуль word_app анализирует мультимодальность текстов до их добавления на сайт, т.е. позволяет авторам оперативно исправить недочеты.
Модуль word_app реализован с помощью библиотеки Aspose Word, которая позволяет представить документ в виде объектной модели – дерева, где страница разбивается на параграфы, а параграфы на отдельные стилистические блоки.
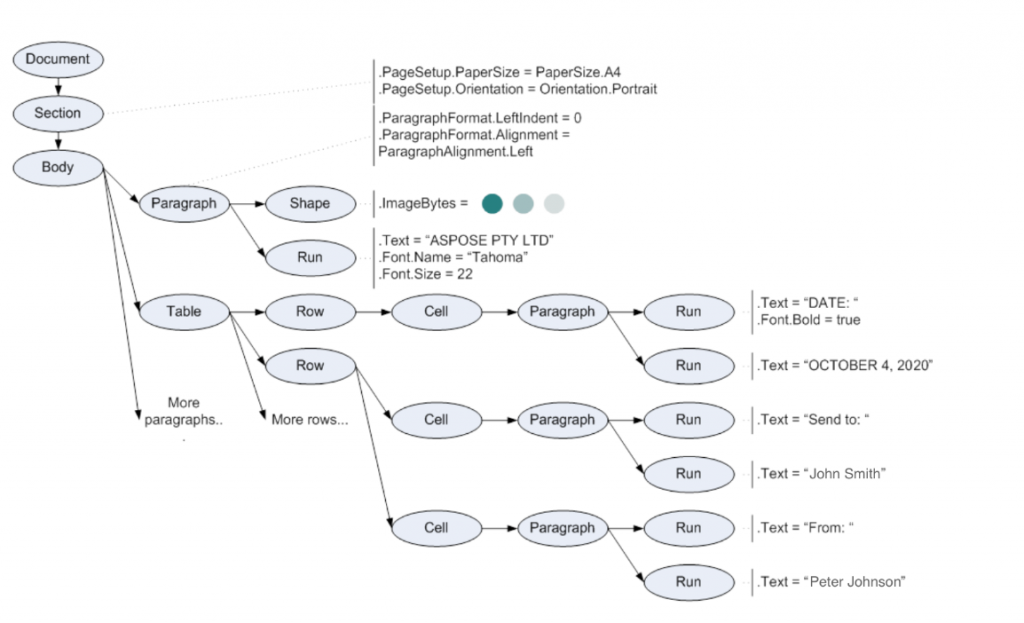
Объектная модель документа
Детали
Нейросетевая модель для каждой из опций была обучена на отдельном датасете (корпусе текстов), а также имеет свою градацию оценки. При использовании первой опции сервис оценивает текст по пятибальной шкале и присваивает ему один из пяти классов:
- Класс 1. Текст крайне сложен для восприятия: текст нуждается в серьезном пересмотре и последующей переработке.
- Класс 2. Текст довольно сложен для восприятия: многое стоит откорректировать, чтобы текст воспринимался легче.
- Класс 3. Текст нуждается в доработке: текст среднего качества, требуются структурные изменения.
- Класс 4. Текст довольно легок для восприятия: хорошо воспринимается, однако нуждается в незначительных корректировках.
- Класс 5. Текст легок для восприятия: написан просто и доступно, изменений не требуется.
PolyLing также предлагает оценку текста по параметру визуального восприятия. Данная опция позволит выяснить, насколько эффективно заданный текст способствует привлечению и удержанию внимания пользователя с точки зрения визуального оформления. Для этого с помощью переключателя над полем ввода необходимо изменить режим проверки удобочитаемости текста на режим оценки визуального восприятия. На следующем этапе предлагается выбрать один из двух форматов оценки визуального восприятия:
- Анализ docx-файла– позволяет оценить визуальную воспринимаемость текста напрямую из текстового файла Microsoft Word с уже выполненными в нем разметкой и графическим оформлением.
- Анализ по ссылке – предоставляет возможность оценить материал, уже размещенный на веб-сайте, по URL-ссылке.
Процесс оценки визуального оформления текстового контента осуществляется посредством командной кнопки «Анализировать», соответствующий аналогичной кнопке в режиме оценки «Анализ текста». По итогам анализа алгоритм возвращает пользователю численную оценку – количество пунктов, удовлетворяющих референсным значениям критериев мультимодальности, – и один из трех классов:
- зеленый – 9-11 пунктов– отличное оформление, обеспечивающее хорошее восприятие контента;
- желтый – 5-8 пунктов– – оформление текста следует доработать для достижения наилучшего восприятия пользователем;
- красный – 0-4 пунктов – оформление текстового материала затрудняет восприятие, в связи с чем нуждается в исправлении.
Технологии
| Языки программирования и фреймворки: | Python, Typescript, Nest.js, React.js, Flask |
| OS: | Кроссплатформенная |
| Протоколы обмена данными: | REST |
| DevOps: | Docker, Docker-compose, Kubernetes |
| Библиотеки: | Beautiful Soup, request, Aspose.Words, NumPy |
РИД
Публикации
Ключевые исполнители
Руководитель проекта: А.В. Рубцова, доктор педагогических наук, профессор, директор Высшей школы лингводидактики и перевода Гуманитарного института СПбПУ
Руководитель группы программной разработки: М.В. Болсуновская, заведующий Лабораторией «Промышленные системы потоковой обработки данных» Центра НТИ СПбПУ
Исполнители
- Высшая школа лингводидактики и перевода Гуманитарного института СПбПУ
- Лаборатория «Промышленные системы потоковой обработки данных» Центра НТИ СПбПУ